プロンプトによるバレ消し
Kling O1の精度に感心しつつも、新たな壁にぶつかる
アクションシーンのVFXワークに付きものなのが、ワイヤー消しです。ワイヤーを用いたアクションシーンの実写プレートを受け取ったら、役者が装着したハーネスなどのワイヤーを1フレームずつ手作業で消していくのが基本で、今でも大きな工数を要します。また、消したい箇所の奥にある服のシワや背景の複雑なテクスチャを再現する必要もあるため、レタッチのスキルも求められます。
そんな手間のかかるバレ消し作業を「Kling O1」で試してみました。Kling O1では、動画と短いプロンプトを入力するだけで、指定した要素をほぼ全自動で消すことができます。驚くべきはその整合性の高さで、ハーネスで引っ張られることで生じていた服のシワが自然に修正されるのはもちろん、消した先のボタンやリフレクションまで再現されるケースも見られました。多少のモーションブラーがある素材や、フォーカスが移動する素材にも対応できました。
ただし、商業制作での利用にはいくつかの注意点があります。Kling O1はHDに限られます。4K素材に対応するには、画面を左右半分ずつクロップしてそれぞれ生成した上で、コンポジットソフトで合体させるといった工夫が必要です。また、画像生成AIは8ビットで処理されるため、事前にコントラストを弱め、白飛びや黒つぶれが起きないようコンポジットソフト側でケアしてから処理することも欠かせません。
さらに、プロンプトによるバレ消しを試していくなかで、大きな壁にもぶつかりました。「ワインを飲む人物だけを消して、ワイングラスとボトルは残す」といった、複数の要素を選択的に扱う指示は難易度が高く、思い通りに制御することができなかったのです。



ComfyUIによるバレ消し
ノードベースによる制御で、意図した画を作り出す
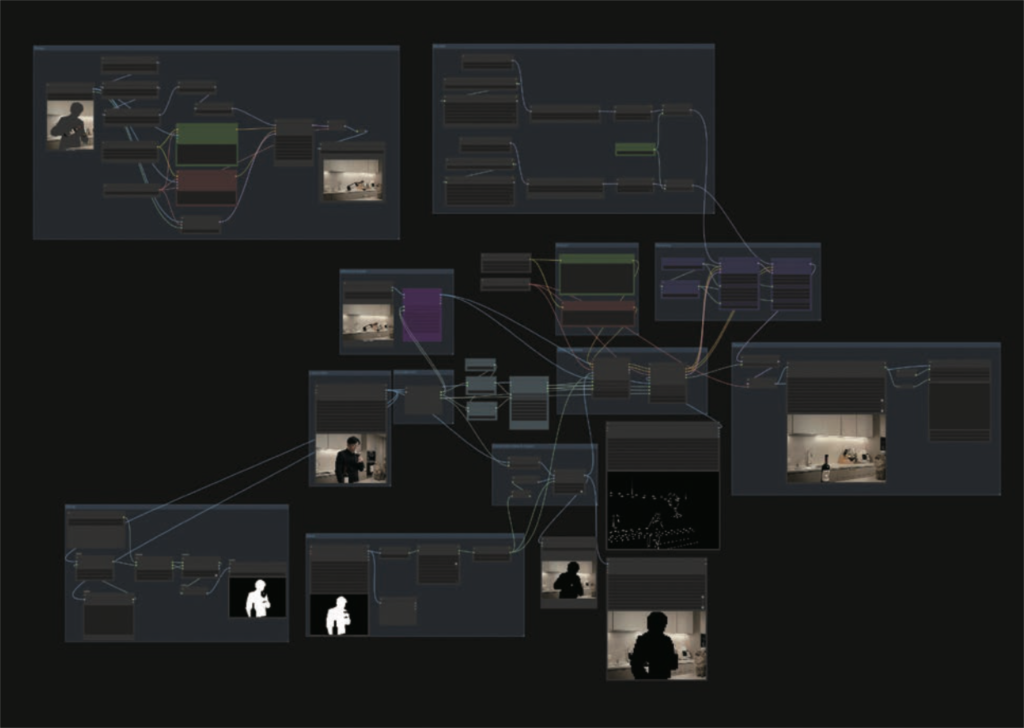
商業用途では、クラウドサービスのAIは使用許可が下りないケースがほとんどだと思います。そこで私はローカル環境で動作するAIツール「ComfyUI」を活用しています。ComfyUIはNukeに近いノードベースの操作体系を持ち、シンプルなノードを組み合わせることで複雑な処理が実現できます。Kling O1がプロンプトだけで処理を行うのに対し、ComfyUIでは自分で制御フローを設計できるため、意図した結果をより確実に得ることができます。
Kling O1ではどうしても実現できなかった「ワインを飲む人物だけをリムーブする」という処理も、ComfyUIで制御フローを組むことで対応できました。ComfyUIによるワークフローは、大きく3つの要素から構成されています。
まず「静止画リファレンスの作成」です。動画でいきなり生成を試みると時間がかかるうえ、失敗するリスクも高くなります。そこで最初に「消したい要素だけが消えた状態の静止画」を生成し、後の動画生成における指針とします。
次に「マスクの処理」です。SAM2やSAM3といったノードを使って人物のマスクを自動生成しますが、取得したマスクをそのままAIに与えると「人の形=人を生成してOK」とAIが判断してしまいます。これを防ぐために、マスクをあえてブロック状に崩すなど、人のシルエットをAIに認識させにくくすることがポイントです。






Cannyノードを利用する
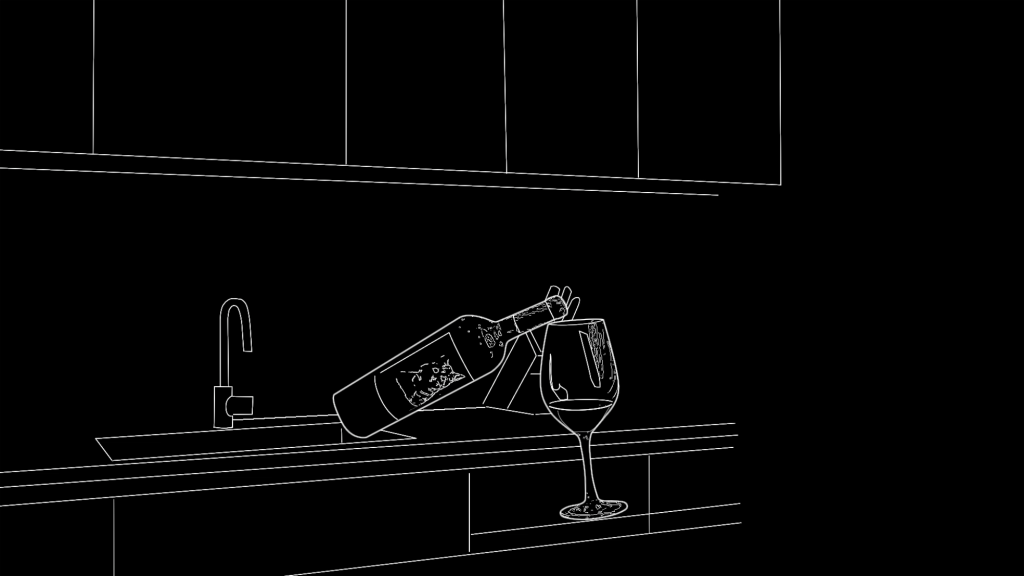
ComfyUIによるバレ消しで私がよく利用しているのが、「Canny(輪郭線)ノード」です。Cannyはエッジ検出アルゴリズムを実装したプリプロセッサで、入力映像のアウトラインを白黒の線画として出力します。このエッジ情報をControlNet(ノードツリー)に渡すことで、「どこに何を残すか」をAIに正確に指示することができます。
Cannyは自動検出でも使えますが、消し込みの場合は「消した後の状態」のエッジが必要なため、Nukeなどで手動作成するのが私のアプローチです。具体的には、静止画リファレンスを基に、シンク・ナイフスタンド・ワインボトルといった残したいオブジェクトのアウトラインをトレースし、ハイライトや映り込みの細かい線まで描き加えます。それをトラッキングで動きに合わせてアニメーションさせたうえで読み込ませると、位置・形・ディテールのすべてをAIに指示したことになります。リファレンスとCannyで情報を与えきってしまえば、プロンプトの有無にかかわらず結果がほぼ変わらない状態になります。人を生成する余地がなくなるため、意図しない人物が出力されることもありません。ガチャの要素をできるだけ排除し、思い通りの結果を安定して得るためにも、各ノードの特性を実際に試しながら覚えていくことが大切です。
生成拡張をオブジェクトトラッキングに利用する
フレームアウトによるトラッキングの分断を防ぐ
Video Outpainting(生成拡張)は、縦型動画の左右を拡張して16:9の横長にするといった用途で知られる処理ですが、VFXの下処理にも活用できます。例えば、被写体がフレームアウトするショットのオブジェクトトラッキング精度を向上させることができます。
役者の顔にタトゥーや傷跡を加えつつ追従させたい場合など、一度フレームアウトして戻ってくる被写体をトラッキングする際には、フレーム端でのデータ崩れや、フレームアウト前後でトラッキングデータが分断されるといった問題が起きがちです。そこで、フレームアウトした領域をアウトペイントして画面外の映像を生成しておくことで、被写体が常にフレーム内に存在する状態を作り出せます。この状態でトラッキングを実行すれば、従来はデータが外れてしまっていたフレームも含めて、途切れなく追従できます。
生成した映像はトラッキングデータの取得にのみ使用するもので、最終出力には含まれません。そのため、生成クオリティはトラッキング用途を満たす最低限で充分です。高速化LoRAを使い、計算ステップ数と解像度を下げて処理することで、作業時間をさらに短縮することもできます。
またNukeのSmart Vectorを用いた処理では、フレームアウトしたピクセルの移動値が追えずに画が伸びてしまう不具合が生じることがあります。アウトペイントで常にフレーム内に情報がある状態を維持しておけば、こうした問題を回避してSmart Vectorを適切に機能させることができます。顔の下半分しか映っていないカットで顔全体にペイントを施したい場合なども、同様にアウトペイントが有効です。
動画生成した元素材





オブジェクトトラッキングした素材






生成拡張のガイド



生成拡張された結果



拡張されたことで、トラッキングが外れない。この後、元の画角にトリミングする
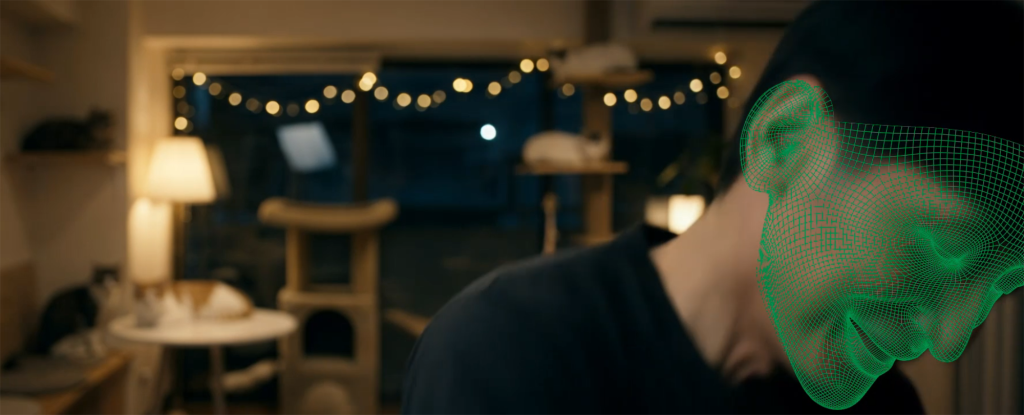

画ブレやスタビライズにも利用できる
アウトペイントは、画ブレ(カメラシェイク)やスタビライズにも応用できます。従来、後処理で画ブレを付ける場合はプレートの端が足りなくなるため、画を拡大せざるを得ませんでした。しかしプレートを拡大すると、撮影監督が現場で決めた構図を崩してしまう恐れがあります。映像制作は多くの部署が連携して成り立つものであり、私がコンポジット作業を行う際も、自分たちの都合で他部署のクリエイティブを損なわないよう心がけています。
アウトペイントを使えば、あらかじめ周囲に余白を生成しておくことで、元の構図を一切変えずに画ブレを加えることができます。スタビライズで位置調整が生じる場合も同様で、拡大せずに揺れだけを抑えることが可能です。ただし、画ブレ中に生成した領域が一瞬映り込むことになるため、画的にはトラッキング用途よりも高精度が求められます。



LoRAによるFace Swap
生成する度に顔が変わることを回避
LoRA(Low-Rank Adaptation)は、既存のAIモデルに追加で学習を行う技術です。大規模モデルの全パラメータを再学習することなく、少ないコストで特定の情報を追加で覚えさせることができます。このLoRAが特に有効なのが、顔の置き換え(Face Swap)です。特定の人物の顔を、さまざまな角度・表情・ 照明条件・屋内外のシチュエーションで撮影した写真を数十〜数百枚用意してAIに学習させます。学習が完了したLoRAを動画生成に組み合わせると、どのようなシーンでも同じ顔で安定した生成が可能になります。
Face SwapのComfyUIワークフローは、まず対象映像から顔マスクを取得し、続いて骨格・ポーズ・顔の輪郭といった情報をControlNetで検出・生成します。このとき、バレ消しと同様に、綺麗すぎるマスクは元の人物のシルエットにAIが引っ張られる原因となるため、ブロック処理で崩しておきます。LoRAとControl Netを組み合わせることで、元の体は変えずに顔だけを差し替えることができます。物体が顔に被さった状態でも、AIが前後のフレームから補完して自然に処理します。
LoRA作成にはコマンドラインによる操作が必要なケースもあり、プログラミングに不慣れな方にはハードルが高く感じられるかもしれません。しかし一度作成してしまえば、Face Swap・アップスケール・スタイル変換など、多様な用途に横断して活用できます。最近は、GUIベースでLoRAを利用できるツールもあるみたいです。




アップスケール(超解像処理)
使い方次第では、有効な選択肢に
LoRAは、アップスケール処理にも有効です。解像度や書き込みを上げると学習モデルに引っ張られて顔が変わってしまうことがありますが、LoRAで本人の情報を与えることで、顔の特徴を保持したままアップスケールが可能になります。
顔に限らず、小道具のデザインなど変えたくない要素のLoRAをあらかじめ作成しておけば、どれだけ書き込みを加えても元のオブジェクトの情報を維持することができます。


コンセプトアートでアイデアを膨らませる
AIで方向性を可視化してチームの目線を合わせる
最後に紹介するのが、AIによるコンセプトアート作成です。監督から「建物を猫のデザインにしたい」といった漠然としたイメージが提示されたとき、闇雲に作り始めるのは非効率です。従来は画像検索でリファレンスを集めながら方向性を探っていましたが、AIを使えば「実際のロケ地にCGを合成すると、どのような見た目になるか」といったことを短時間で可視化できます。
この段階では、生成物のクオリティ自体は重要ではありません。方向性を絞り込み、チームで目線を合わせることが目的だからです。AIで出力したイメージを共有して「これは良い・これは違う」といったことをすり合わせることによって、CG・VFXワークの手戻りを減らしながらクオリティを詰めていくこ とができます。
ただし、AIはあくまで架空のビジュアルを生成するものである点には注意が必要です。実写でもアニメーションでも最終的なクオリティの拠り所は、現実のリファレンスに置くことが大切でしょう。



